Textanalyse
Jede Unterseite wird einigen ausführlichen textuellen Prüfungen unterzogen
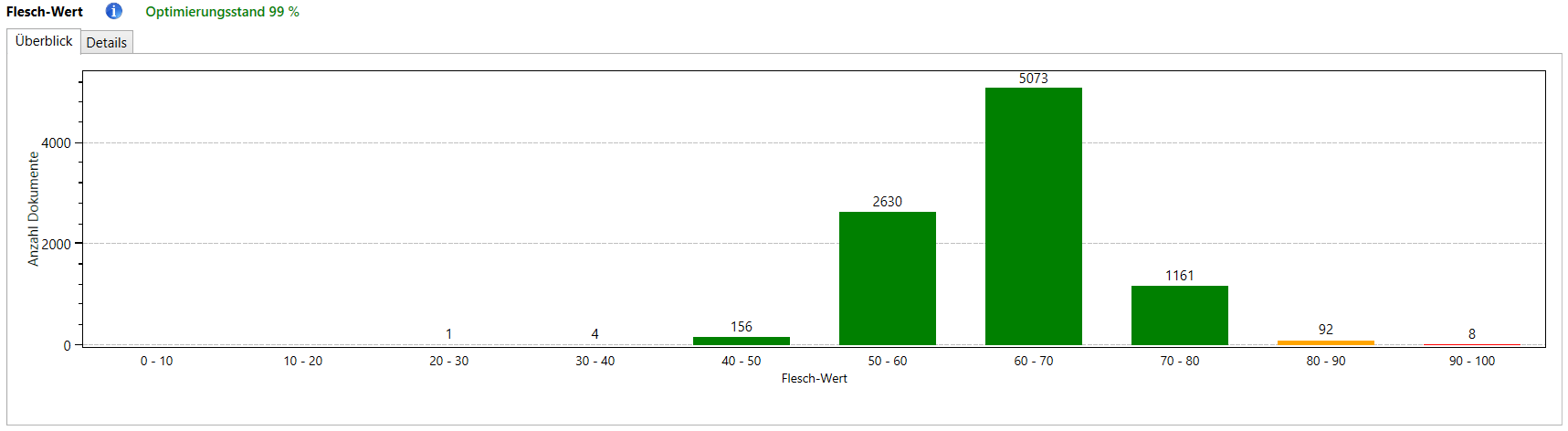
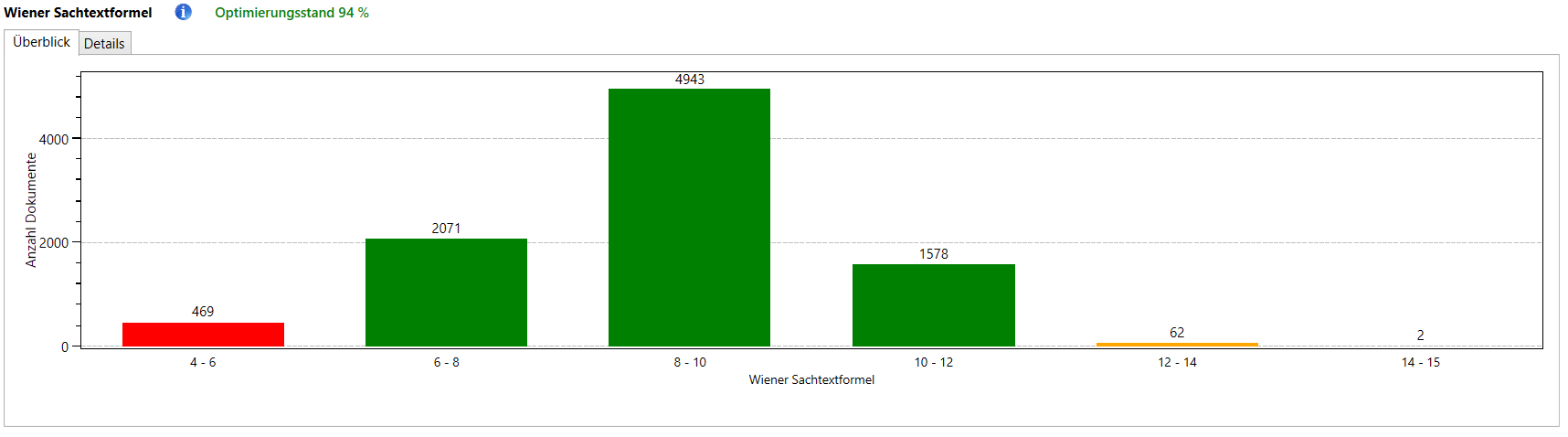
Alle Dokumente werden einer Lesbarkeitsanalyse nach den Metriken Flesch-Index und Wiener Sachtextformel unterzogen. Diese Metriken bewerten, wie einfach ein Text zu verstehen ist.
Generell gilt: einfacher zu verstehende Texte werden häufiger gelesen und die Gefahr, dass ein Nutzer wegklickt, ist geringer.
Kritisch sind dabei sehr schwer verständliche sowie triviale Texte. Das Vorhandensein von vielen extrem trivialen Texten kann als negativer Qualitätsfaktor gewertet werden, z.B. beim Panda-Update.
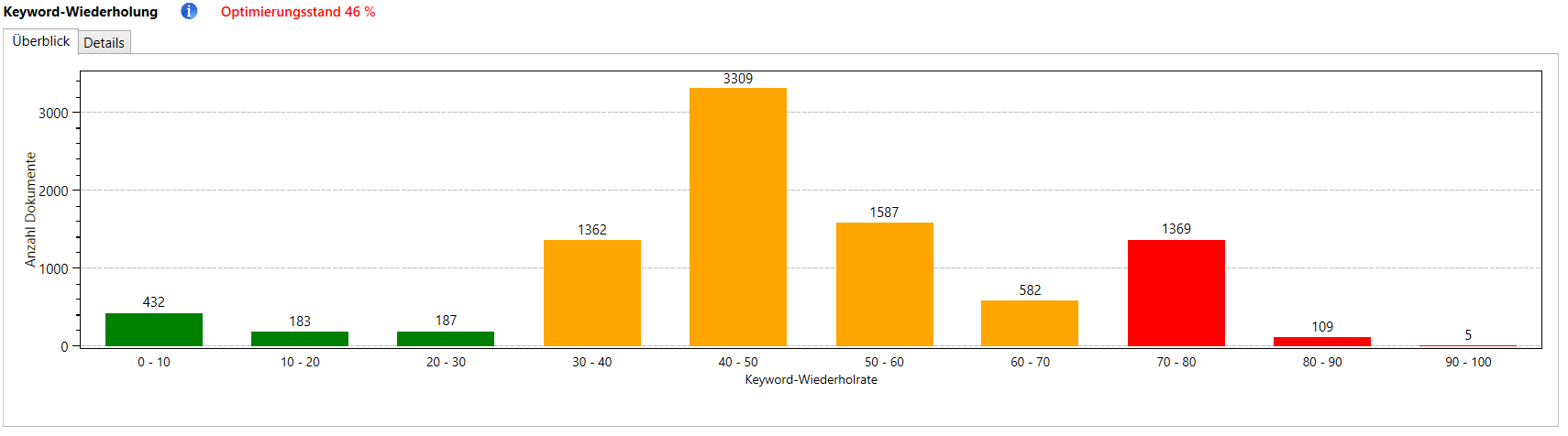
Es wird für alle Terme im Text geprüft, wie schnell sie sich wiederholen. Die Wiederholrate gibt den Anteil der Terme an, die sich im Text innerhalb der darauf folgenden 15 Wörter wiederholen. Stoppwörter werden hierbei ausgeschlossen, da sie auch auf natürliche Weise sehr oft in Texten vorkommen können und sich schnell wiederholen.
Wenn sich viele Terme sehr schnell im Text wiederholen, kann das ein stilistischer Mangel sein.
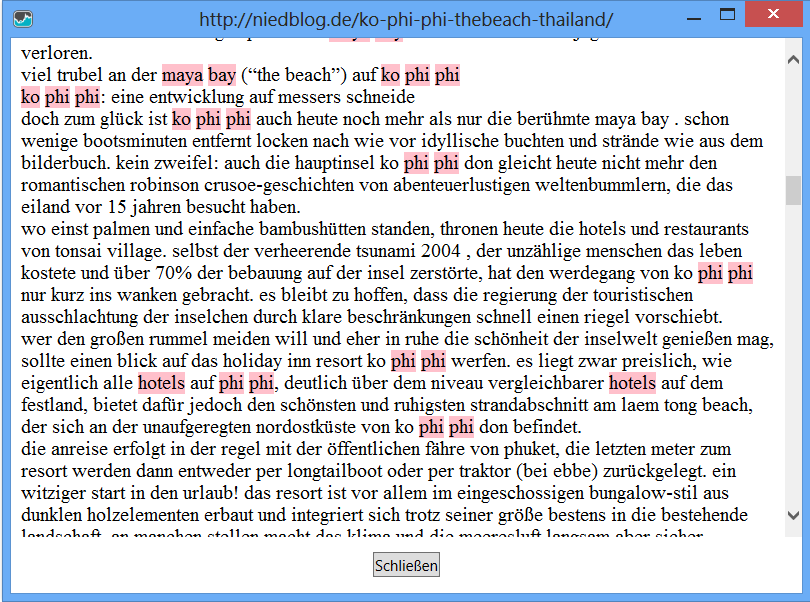
Sie können sich für jedes Dokument genau anzeigen lassen, welche Terme sich schnell wiederholen. So können solche stilistischen Mängel gegebenenfalls schnell behoben werden.
Die Analyse kann im übrigen auch auf Keywords (das sind in dem Fall die beiden am häufigsten verwendeten Terme in einem Dokument) beschränkt werden. So können Sie Keyword-Stuffing auch dann aufdecken, wenn es nur einen Teilbereich eines Dokumentes betrifft und damit durch eine Keyword-Density-Analyse nicht aufgefallen wäre.
Wenn Sie schnell den Messwert einer einzelnen Seite bestimmen wollen, können Sie das direkt online mit dem SEO-Schnellcheck tun.
Informationsgehalt
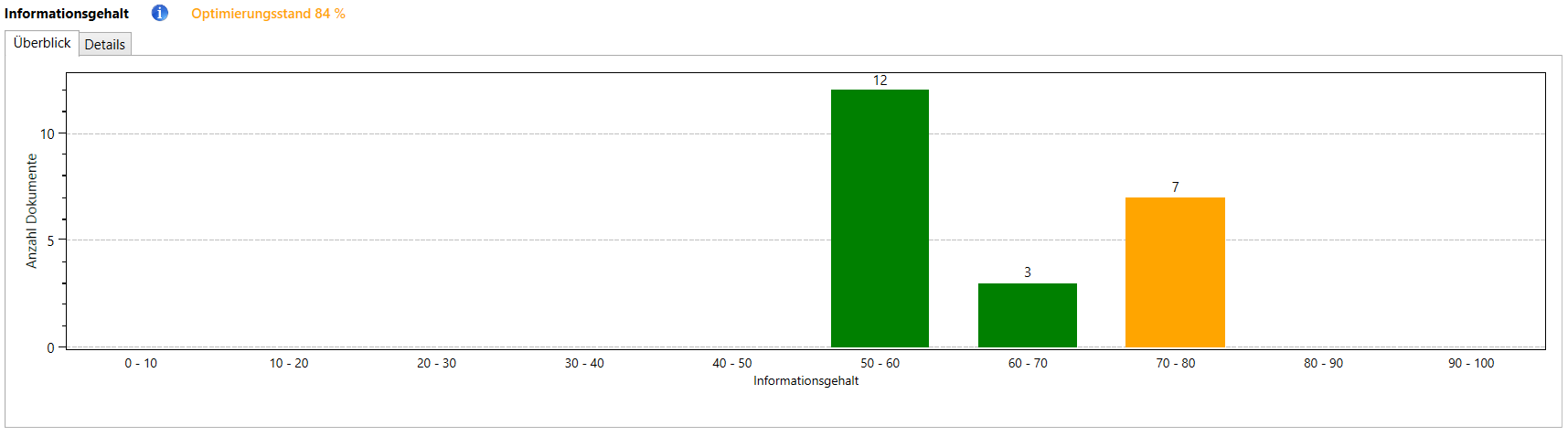
Der Informationsgehalt gibt an, ob ein Text eher oberflächlich geschrieben ist oder ob er tiefergründige Informationen liefert.
Es werden dafür alle verwendeten Terme analysiert: werden viele sehr allgemeine Terme verwendet (wie z.B. ‚ich‘, ‚Auto‘ oder ‚Garten‘) erhält der Text einen niedrigen Wert, sind dagegen viele sehr spezifische Begriffe vorhanden (wie z.B. ‚Hundehalsband‘, ‚Dampfschifffahrt‘ oder ‚Zylinderkopfdichtung‘) steigt der Informationsgehalt an.
Ein Text mit einem höheren Informationsgehalt ist nicht automatisch besser (z.B. kann man den Wert durch die Verwendung vieler schwer verständlicher Fremdwörter erhöhen), man sollte hauptsächlich darauf achten, ob es Texte mit sehr niedrigem Informationsgehalt gibt.
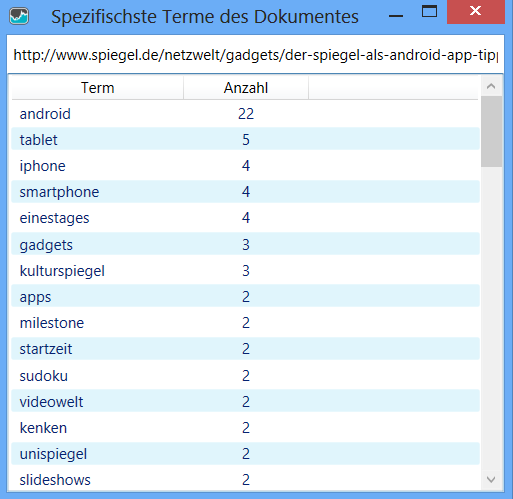
Sie können sich in der Detailansicht übrigens für jedes Dokument die spezifischsten Terme anzeigen lassen.
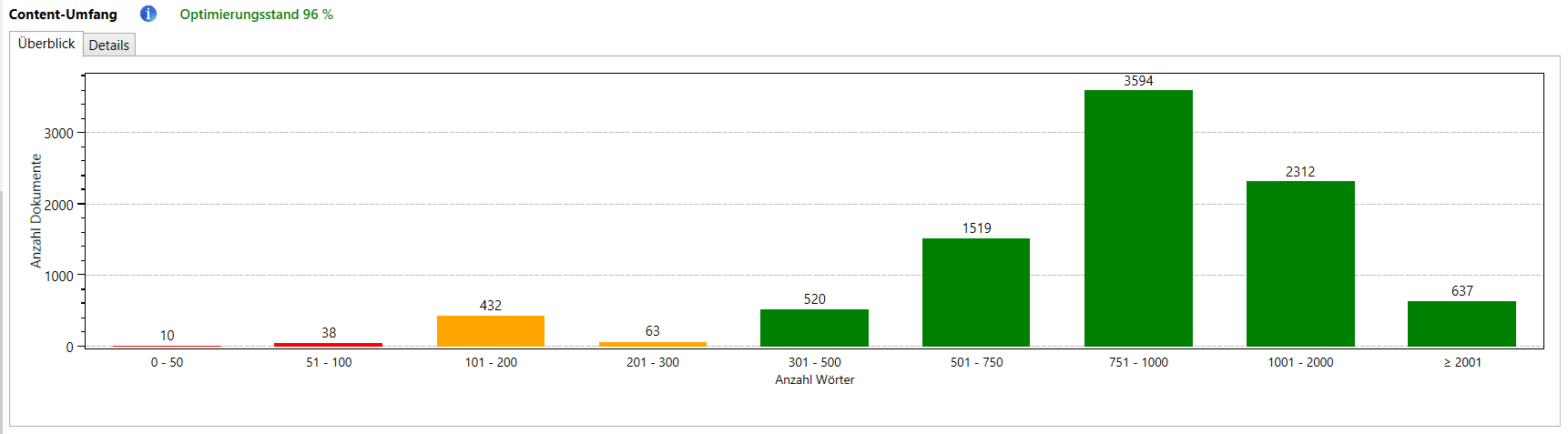
In diesem Report werden die Textlängen der analysierten Dokumente dargestellt. So finden Sie leicht sehr kurze Dokumente, die möglicherweise als „Thin Content“ gewertet werden können.
Bei sehr kurzen Dokumenten sollten Sie überlegen, ob es Sinn macht, diese zu erweitern. Wenn ein Dokument keine oder kaum nützliche Informationen enthält, kann es auch Sinn machen, das Dokument ganz zu löschen oder z.B. per noindex von der Indexierung auszuschließen.
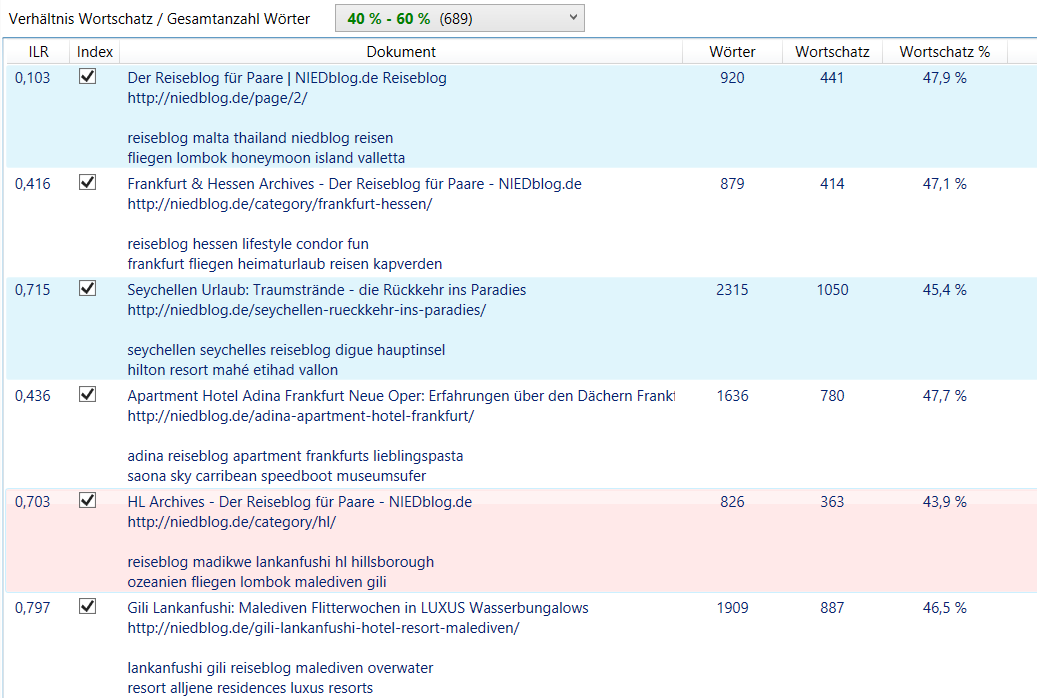
Außerdem wird der Wortschatz untersucht, d.h. die Anzahl der unterschiedlichen Terme. Dabei wird die Größe des Wortschatzes ins Verhältnis gesetzt zur Gesamtanzahl der Wörter in einem Dokument. Es ist normal, dass dieses Verhältnis sinkt, je länger ein Text wird. Erzielen Sie bei einem Text jedoch einen sehr niedrigen Wert (z.B. unter 20%) ist das eventuell eine manuelle Überprüfung wert. Ein sehr niedriger Wert kann auf „Thin Content“ hindeuten, da es ein Anzeichen dafür sein kann, dass ein Text künstlich aufgebläht wurde, indem immer wieder dasselbe geschrieben wird.
Alleinstellungsmerkmale
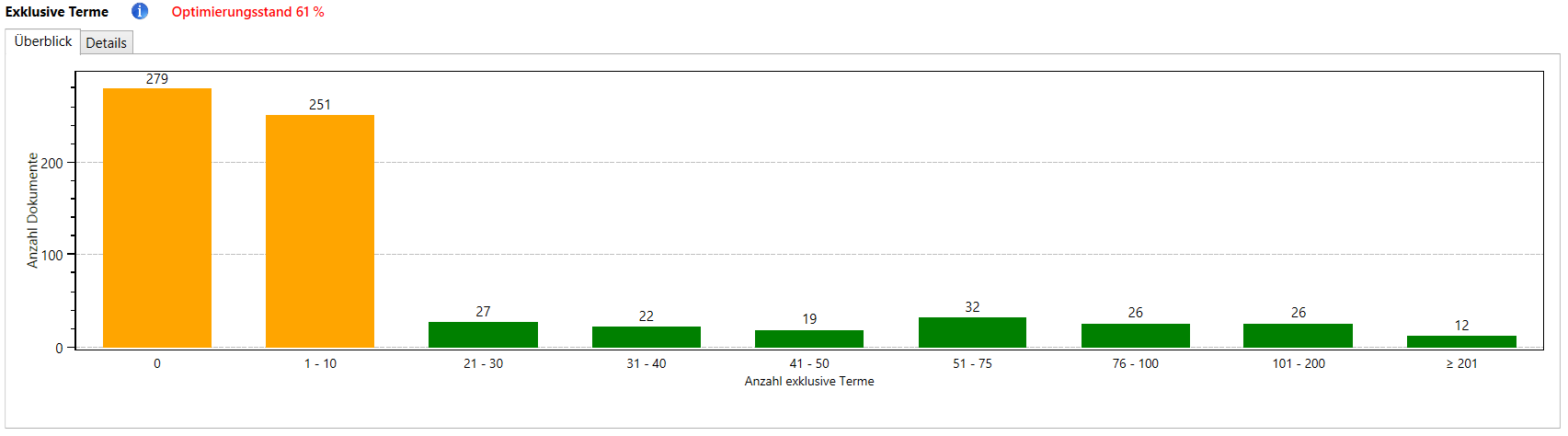
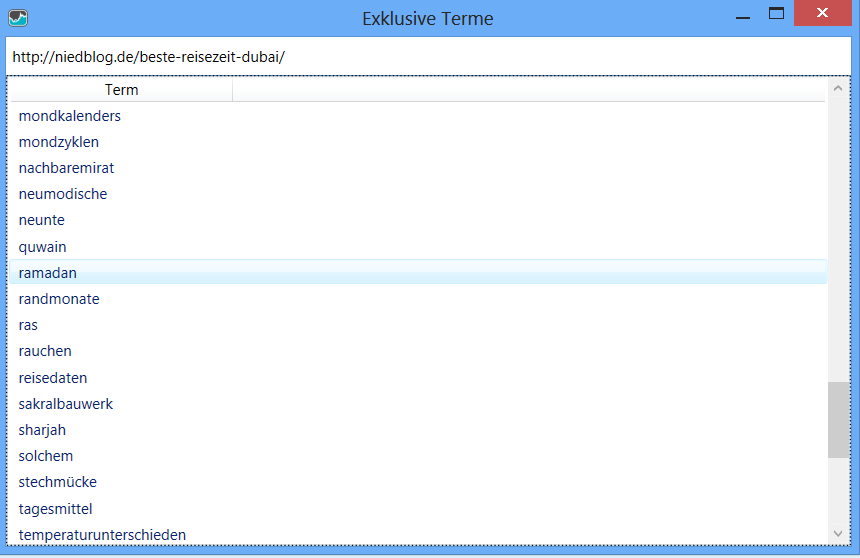
In diesem Report wird für jedes Dokument angegeben, wie viele exklusive Terme es besitzt. Ein exklusiver Term ist ein Term, der sich nur auf einer Unterseite der Domain befindet und auf sonst keiner anderen Unterseite.
Gute Dokumente sollten immer auch Alleinstellungsmerkmale besitzen, also (Unter-) Themen behandeln, die es sonst auf keiner anderen Seite der Domain gibt.
Wenn Ihre Domain Seiten mit sehr wenigen oder gar keinen Alleinstellungsmerkmalen besitzt, sollten Sie überlegen, ob es eventuell Sinn macht, die Inhalte so zu erweitern, dass sie neue und bisher nicht gekannte Teilbereiche der Themen abdecken.
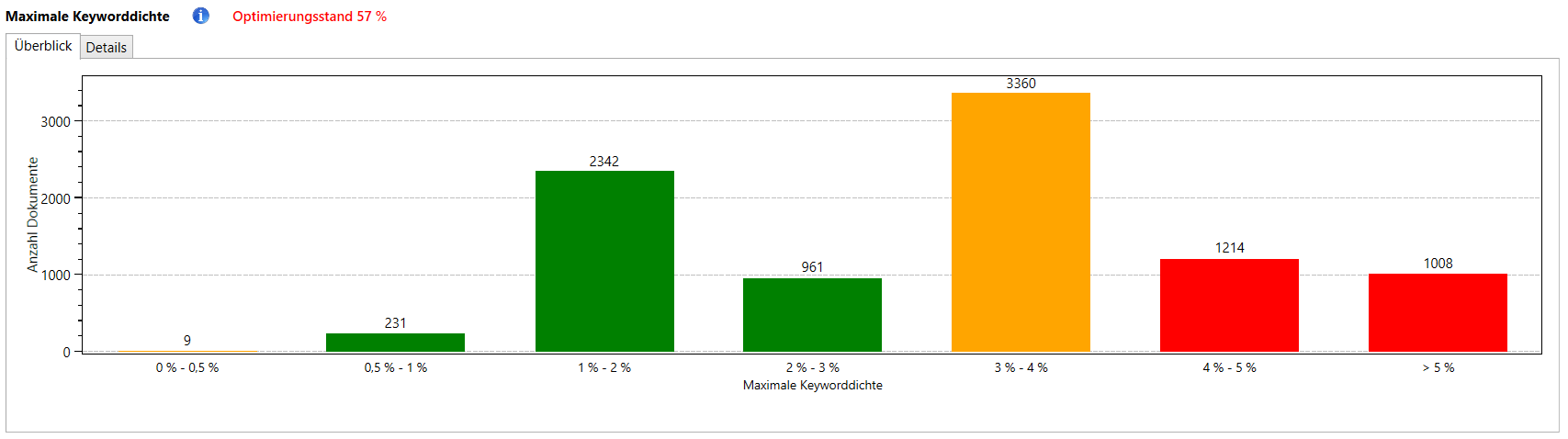
Die Keyworddichte ist zwar mittlerweile kein Merkmal mehr, auf das man explizit hin optimieren sollte. Jedoch eignet sich die Keyworddichte nach wie vor sehr gut dafür, Spamsignale, die von Dokumenten ausgehen, aufzudecken. Wenn Texte regelrecht mit Keywords vollgestopft werden, wird dies höchstwahrscheinlich als sehr negatives Qualitätsmerkmal gewertet.
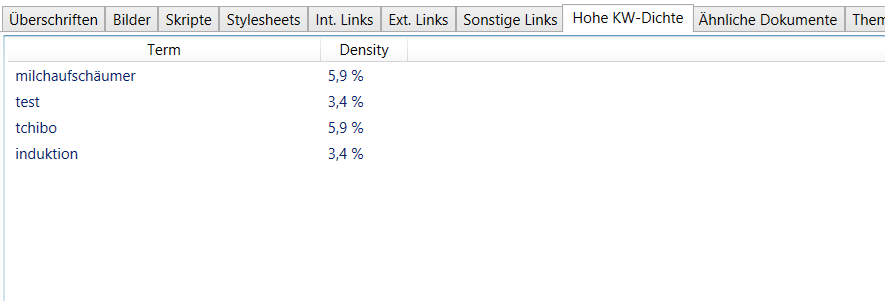
In diesem Report wird für jedes Dokument die maximale Keyworddichte eines Terms berechnet. Stoppwörter werden dabei außen vor gelassen: diese können auf natürliche Weise sehr häufig in einem Dokument vorkommen und eignen sich daher nicht zur Erkennung von Spamsignalen.
Generell gilt: Keyworddichten von über 4% sollten heute in Webdokumenten nach Möglichkeit vermieden werden. Auch bei Dichten zwischen 3% und 4% sollten Sie überprüfen, ob Sie den Text nicht verbessern können, indem Sie die Keyworddichte auf maximal 3% senken. Keyworddichten von 3% oder weniger können als unkritisch angesehen werden.